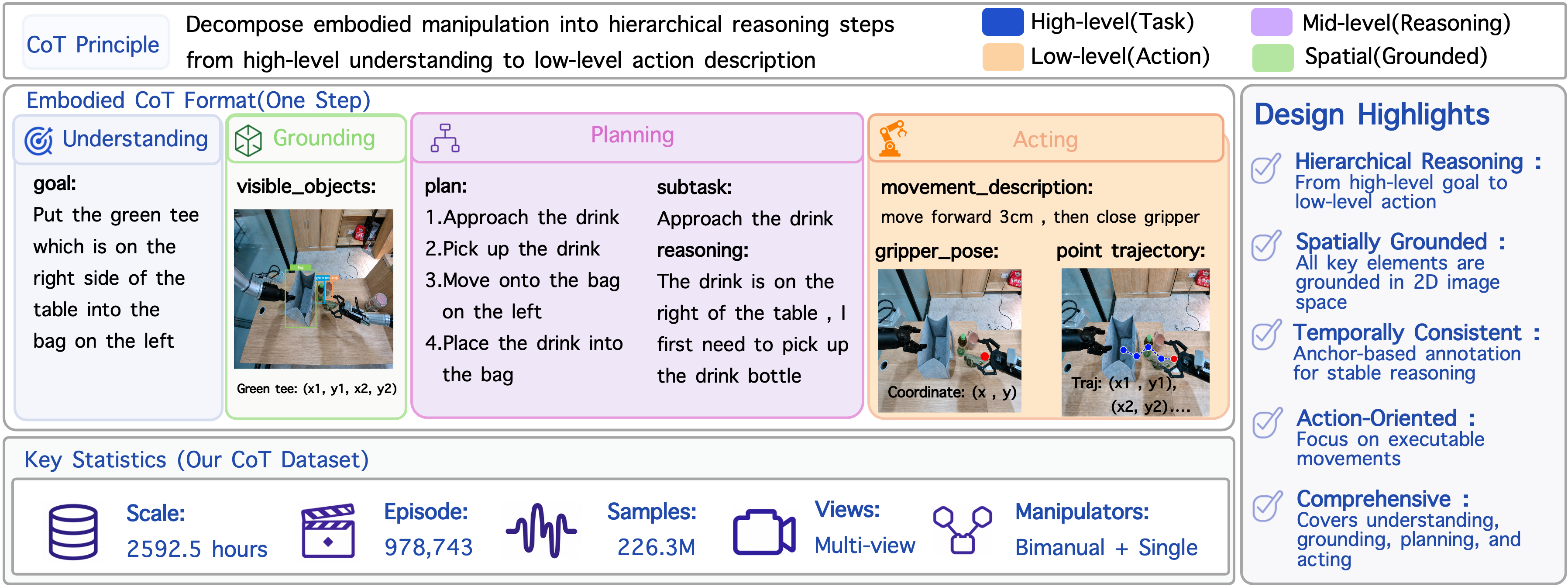

LIBERO-Plus Zero-Shot Transfer
We evaluate ERVLA on LIBERO-Plus, where models are post-trained on LIBERO and evaluated by zero-shot direct transfer under task-suite and perturbation shifts. ERVLA reaches a 86.9% total success rate, outperforming strong VLA baselines including OpenVLA-OFT, π0, π0-FAST, PokeVLA, and π0.5. The gains are especially clear under out-of-distribution conditions such as camera, robot, language, lighting, background, noise, and layout perturbations.
| Method | Task Suite | Perturbation Type | Total Succ. (%) ↑ |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Spatial | Object | Goal | Long | Camera | Robot | Language | Light | Background | Noise | Layout | ||
| ECoT(Zawalski et al., 2024) | 31.8 | 27.9 | 30.6 | 8.6 | 0.3 | 26.8 | 40.2 | 42.6 | 16.4 | 10.2 | 36.9 | 24.3 |
| OpenVLA-OFT(Kim et al., 2024) | 84.0 | 66.5 | 63.0 | 66.4 | 56.4 | 31.9 | 79.5 | 88.7 | 93.3 | 75.8 | 74.2 | 69.6 |
| π0-FAST(Black et al., 2025) | 74.4 | 72.7 | 57.6 | 43.4 | 65.1 | 21.6 | 61.0 | 73.2 | 73.2 | 74.4 | 68.8 | 61.6 |
| PokeVLA(Zhu et al., 2025) | 85.4 | 81.8 | 77.6 | 72.7 | 84.7 | 46.1 | 84.8 | 94.6 | 82.6 | 89.8 | 77.2 | 79.3 |
| π0.5(Black et al., 2025) | 90.4 | 89.9 | 81.0 | 80.8 | 71.7 | 75.5 | 85.9 | 96.1 | 95.7 | 86.4 | 87.5 | 85.5 |
| No Choice + Knowledge Isolation | 83.8 | 78.6 | 71.4 | 69.0 | 80.4 | 43.8 | 81.0 | 91.6 | 79.2 | 85.4 | 74.6 | 76.5 |
| Choice + No Knowledge Truncation | 89.2 | 88.6 | 79.4 | 79.8 | 70.8 | 73.4 | 84.6 | 94.2 | 94.4 | 85.6 | 86.2 | 84.7 |
| ERVLA (Ours) | 96.2 | 89.6 | 79.6 | 82.1 | 77.2 | 75.3 | 87.1 | 95.1 | 94.7 | 92.3 | 86.4 | 86.9 |
Table 1: Quantitative comparison on LIBERO-Plus. Models are post-trained on LIBERO and evaluated by zero-shot direct transfer across task suites and perturbation types. ERVLA obtains the best total success rate.
Background Textures
Sensor Noise
Object Layout
Camera Viewpoints
Robot Initial States
Light Condition
VLABench Generalization
VLABench evaluates semantic and distribution-shift generalization across in-distribution, cross-category, commonsense, instruction-following, and texture-variation tracks. ERVLA achieves the best average success rate, progress score, and intention score among compared methods, showing that embodied CoT is most useful when it becomes an action-relevant representation rather than a mandatory autoregressive explanation.
| Method | Success Rate by Track (%) ↑ | Average ↑ | ||||||
|---|---|---|---|---|---|---|---|---|
| In-dist. | Category | Common | Instruction | Texture | SR | PS | IS | |
| π0(Black et al., 2024) | 47.0 | 21.2 | 29.1 | 17.3 | 32.2 | 29.4 | 44.1 | 55.0 |
| π0-FAST(Black et al., 2025) | 56.2 | 31.0 | 38.0 | 35.0 | 39.0 | 39.8 | 49.5 | 58.6 |
| ACoT-VLA(Zhang et al., 2025) | - | - | - | - | - | 47.4 | 63.5 | - |
| π0.5(Black et al., 2025) | 65.4 | 38.2 | 43.9 | 48.2 | 44.9 | 48.1 | 62.3 | 64.9 |
| Choice + No Knowledge Truncation | 62.0 | 42.4 | 43.0 | 53.6 | 35.0 | 47.2 | 59.8 | 63.4 |
| ERVLA (Ours) | 69.7 | 47.0 | 44.0 | 58.0 | 47.4 | 53.2 | 65.9 | 70.4 |
Table 2: Comparison on VLABench. SR, PS, and IS denote success rate, progress score, and intention score. ERVLA obtains the strongest average performance across semantic and distribution-shift tracks.
Track 1: In distribution
Add bbq-sauce to the dish
Insert the rose into the vase_seen.
Track 2: Cross Category
Add hotsauce to the dish
Insert the daisy_flower into the vase_unseen.
Track 3: Commonsense Reasoning
The flavors in this dish are quite mild, it would benefit from something that adds a bold and tangy character.
Find the exquisite flower associated with admiration and place it gracefully into the vase.
Track 4: Semantic Instruction Following
While packing the picnic basket, don't forget to include something for the sandwiches that adds a zesty twist.
It's my mother's birthday today. She loves chrysanthemums. Please take the freshest chrysanthemums you can find and place them in her favorite vase as a surprise.
Track 5: Unseen Texture Variation
Add bbq-sauce to the dish
Insert the rose into the vase_seen.
VLM-to-VLA Transfer and CoT Scaling
We study whether embodied CoT can turn stronger vision-language models into stronger action policies, and whether this supervision scales with more pre-training data. On diverse VLM backbones evaluated under a unified interface, performance without explicit CoT shows only weak or even negative correlation with VLM capability on LIBERO and VLABench. With embodied CoT supervision, stronger VLMs transfer more reliably: the best results are dominated by the Qwen3-VL family, indicating that CoT acts as a transfer interface that converts semantic priors into action-relevant representations rather than merely adding extra text.
Naive autoregressive CoT plus action-token decoding does not scale reliably as more robot CoT data is added. ERVLA instead uses CoT as representation-shaping supervision together with a choice branch, knowledge truncation, and flow-based action learning. As embodied CoT pre-training grows from 35M to 226.3M samples, ERVLA improves steadily on both LIBERO-Plus and VLABench, whereas autoregressive CoT+FAST and isolated VLM+DiT baselines show weaker or saturated scaling.
Figure 3: VLM-to-VLA transfer and embodied CoT scaling. Left: ECoT better aligns VLM capability with action. Right: ERVLA scales steadily with more CoT data on both LIBERO-Plus and VLABench, whereas AR CoT+FAST and isolated VLM+DiT show weaker or saturated scaling.
Real-World Evaluation
We also deploy ERVLA on physical robots using one third-person camera and one wrist camera. The real-world task suite includes placing items into drawers and clearing tabletop waste across four tiers: Basic, Distractors, Semantic, and Long-horizon. The main gap appears under semantic ambiguity, distractors, and long-horizon dependencies, where ERVLA benefits from internalized embodied reasoning and cleaner diffusion-policy conditioning.
Put the toy car into the drawer.
Put the toy into the drawer.
Put the toy into the lower drawer.
Put the non-toy items into the upper drawer, and put the toys into the second drawer.